| 00:21.59 | *** join/#brlcad konrado_ (~konro@41.205.22.58) | |
| 00:30.58 | *** join/#brlcad vasc (~vasc@bl12-167-49.dsl.telepac.pt) | |
| 00:31.04 | vasc | the quartic solver is broken |
| 00:31.20 | vasc | bn_poly_quartic_roots |
| 00:32.13 | vasc | because bn_poly_quartic_roots is broken what gets called to solve the equation on a quartic when you call rt_poly_roots is actually bn_poly_findroot |
| 00:32.19 | vasc | which uses Laguerre's method |
| 00:33.04 | vasc | anyway i'll cleanup the cubic and quadric code with code i got from numerical recipes in C |
| 00:33.16 | vasc | i'm still banging on how to do the proper quartic solver |
| 00:35.53 | vasc | hm nevermind |
| 00:35.57 | vasc | i found my bug :-P |
| 01:23.19 | starseeker | vasc: IIRC, the numerical recipes in C code is not compatibly licensed |
| 01:24.25 | starseeker | in fact, very much NOT compatibly licensed |
| 01:24.46 | starseeker | i.e. not usable :-( |
| 01:25.52 | vasc | hm |
| 01:26.04 | vasc | well we already in svn quadric solver uses their code |
| 01:26.08 | vasc | kinda |
| 01:26.16 | vasc | i can revert the cubic root one |
| 01:26.23 | starseeker | the regular code or the opencl code? |
| 01:26.35 | vasc | it's buggy anyway |
| 01:26.39 | vasc | the regular one |
| 01:26.45 | vasc | it uses the same algorithm... |
| 01:26.50 | vasc | except it supports imags |
| 01:26.59 | starseeker | same algorithm sure, but we have to stear clear of the code |
| 01:27.33 | vasc | which code? i wrote it by reading the book in maths |
| 01:27.45 | vasc | i didn't use code samples |
| 01:28.55 | starseeker | vasc: when you say "uses their code" that has a pretty specific meaning - generally, it's not "independent implementation of mathematical algorithm" |
| 01:28.56 | vasc | its kind of a shame. the code had less branches but it has some z-shit |
| 01:29.20 | vasc | uh |
| 01:29.22 | vasc | sure whatever |
| 01:29.26 | vasc | i didn't copy c code |
| 01:29.55 | starseeker | nods |
| 01:30.09 | vasc | http://www.it.uom.gr/teaching/linearalgebra/NumericalRecipiesInC/c5-6.pdf |
| 01:30.11 | vasc | i used this |
| 01:30.16 | vasc | section 5.6 |
| 01:30.37 | vasc | and then i optimized it |
| 01:30.48 | vasc | and it seems to have a bug... |
| 01:30.50 | vasc | my code |
| 01:30.53 | starseeker | ah |
| 01:36.42 | vasc | bah |
| 01:36.44 | vasc | revert time |
| 01:38.26 | vasc | it had so many less branches :-( |
| 01:41.12 | vasc | i think its because of how B is computed |
| 01:41.14 | vasc | i'll try something else |
| 01:41.54 | vasc | ah whatever. it ends up being the same... |
| 01:41.55 | vasc | kind of |
| 01:42.01 | Stragus | BRL-CAD's original C code was too branchy? |
| 01:42.33 | Stragus | They made sure that code was pretty accurate even in pathological cases and such, you'll have to be careful if you use new code |
| 01:43.05 | vasc | hm |
| 01:46.05 | *** join/#brlcad kintel (~kintel@unaffiliated/kintel) | |
| 01:46.11 | vasc | geez |
| 01:48.25 | vasc | damned insidious glitch |
| 02:00.12 | vasc | duh |
| 02:00.15 | vasc | it looks great |
| 02:00.26 | vasc | so the problem is calling the quartic solver direct? |
| 02:00.28 | vasc | pathetic |
| 02:02.47 | vasc | just in case i won't replace the cubic solver |
| 02:06.34 | vasc | ah now i see what was the problem |
| 02:08.04 | vasc | its some quartic that is probably close to cubic |
| 02:08.16 | vasc | or some division issues |
| 02:25.23 | vasc | ah whatever |
| 02:26.39 | vasc | in fact both look the same as the code in numerical recipes |
| 02:26.49 | vasc | except they have a lot more tests |
| 02:27.04 | vasc | algorithms |
| 02:29.48 | *** join/#brlcad kintel (~kintel@unaffiliated/kintel) | |
| 03:42.24 | *** join/#brlcad kintel (~kintel@unaffiliated/kintel) | |
| 04:16.39 | *** join/#brlcad gurwinder (~chatzilla@117.212.51.123) | |
| 04:29.57 | *** join/#brlcad konrado (~konro@41.205.22.45) | |
| 04:50.17 | *** join/#brlcad bhollister (~brad@2601:647:cb01:9750:5c7a:866:4799:eae) | |
| 06:06.59 | *** join/#brlcad ries (~ries@D979C47E.cm-3-2d.dynamic.ziggo.nl) | |
| 07:34.53 | *** join/#brlcad ries (~ries@D979C47E.cm-3-2d.dynamic.ziggo.nl) | |
| 09:17.01 | *** join/#brlcad merzo (~merzo@92.60.189.225) | |
| 09:57.59 | *** join/#brlcad ries (~ries@D979C47E.cm-3-2d.dynamic.ziggo.nl) | |
| 10:33.43 | *** join/#brlcad merzo (~merzo@user-94-45-58-141.skif.com.ua) | |
| 10:49.45 | *** join/#brlcad Ch3ck_ (~Ch3ck@154.70.99.129) | |
| 11:34.36 | *** join/#brlcad ih8sum3r (~ih8sum3r@122.173.189.145) | |
| 12:08.43 | *** join/#brlcad Izakey (~Isaac@41.205.22.23) | |
| 12:10.51 | *** join/#brlcad Boquete (~piotr@acmb68.neoplus.adsl.tpnet.pl) | |
| 12:13.13 | *** join/#brlcad sofat (~androirc@101.208.131.132) | |
| 12:29.56 | *** part/#brlcad Izakey (~Isaac@41.205.22.23) | |
| 12:33.34 | *** join/#brlcad merzo (~merzo@user-94-45-58-141.skif.com.ua) | |
| 12:42.25 | *** join/#brlcad sofat_ (~androirc@202.164.45.212) | |
| 12:44.13 | *** join/#brlcad merzo (~merzo@92.60.189.225) | |
| 13:02.13 | *** join/#brlcad teepee-- (bc5c2134@gateway/web/freenode/ip.188.92.33.52) | |
| 13:22.04 | *** join/#brlcad vasc (~vasc@bl12-167-49.dsl.telepac.pt) | |
| 13:25.23 | *** join/#brlcad sofat (~androirc@101.209.194.150) | |
| 13:37.40 | *** join/#brlcad sofat (~androirc@101.209.194.150) | |
| 13:41.18 | *** join/#brlcad kintel (~kintel@unaffiliated/kintel) | |
| 13:47.20 | *** join/#brlcad Boquete_ (~piotr@dwd173.neoplus.adsl.tpnet.pl) | |
| 14:06.38 | *** join/#brlcad ries (~ries@D979C47E.cm-3-2d.dynamic.ziggo.nl) | |
| 14:22.10 | *** join/#brlcad ries (~ries@D979C47E.cm-3-2d.dynamic.ziggo.nl) | |
| 14:25.05 | *** join/#brlcad sofat (~androirc@101.209.194.150) | |
| 14:30.22 | *** join/#brlcad ries_nicked (~ries@D979C47E.cm-3-2d.dynamic.ziggo.nl) | |
| 14:33.10 | *** join/#brlcad sofat (~androirc@101.209.194.150) | |
| 14:34.54 | *** join/#brlcad sofat_ (~androirc@202.164.45.204) | |
| 14:46.31 | *** join/#brlcad ries (~ries@D979C47E.cm-3-2d.dynamic.ziggo.nl) | |
| 14:53.02 | *** join/#brlcad kintel (~kintel@unaffiliated/kintel) | |
| 14:58.26 | *** join/#brlcad sofat_ (~androirc@202.164.45.204) | |
| 15:03.06 | *** join/#brlcad ries (~ries@D979C47E.cm-3-2d.dynamic.ziggo.nl) | |
| 15:03.47 | *** join/#brlcad sofat (~androirc@49.138.136.177) | |
| 15:03.49 | *** join/#brlcad konrado (~konro@41.205.22.20) | |
| 15:12.30 | *** join/#brlcad sofat_ (~sofat@202.164.45.208) | |
| 15:33.41 | *** join/#brlcad Boquete (~piotr@dwd173.neoplus.adsl.tpnet.pl) | |
| 15:34.41 | *** join/#brlcad sofat (~androirc@49.138.136.177) | |
| 15:46.32 | maths22 | I just compiled BRL-CAD on the Raspberry Pi 2 |
| 15:46.36 | maths22 | It works: http://brlcad.org/CDash/buildSummary.php?buildid=198 |
| 15:47.03 | maths22 | Benchmarks are decent: http://brlcad.org/~maths22/bench/run-16638-benchmark.log |
| 15:54.37 | *** join/#brlcad sofat_ (~sofat@202.164.45.208) | |
| 16:01.07 | *** join/#brlcad teepee (~teepee@unaffiliated/teepee) | |
| 16:09.38 | *** join/#brlcad sofat (~sofat@202.164.45.212) | |
| 16:14.24 | *** join/#brlcad dracarys983 (dracarys98@nat/iiit/x-nujuyalijwjubmio) | |
| 16:26.29 | ih8sum3r | ``Erik, brlcad : Can someone please make OGV VM up as I'm getting permission denied error every time, so that I can proceed further. |
| 16:28.43 | *** join/#brlcad Boquete (~piotr@dwd173.neoplus.adsl.tpnet.pl) | |
| 17:12.34 | *** join/#brlcad sofat (~sofat@202.164.45.212) | |
| 17:25.33 | Notify | 03BRL-CAD:vasco_costa * 66073 (brlcad/trunk/src/librt/primitives/arb8/arb8_shot.cl brlcad/trunk/src/librt/primitives/bot/bot_shot.cl and 9 others): add ocl colors to regions. add multi-hit rendering option. |
| 17:26.10 | Notify | 03BRL-CAD:vasco_costa * 66074 (brlcad/trunk/include/rt/defines.h brlcad/trunk/src/librt/primitives/bot/bot_shot.cl and 4 others): support doubles or floats on ocl upon compilation. |
| 17:26.15 | Notify | 03BRL-CAD:brlcad * 66075 brlcad/trunk/src/libbu/parallel.c: need to think through this some more but keith noted projects with recursive parallels where a given child might not actually be done working, thus it should not PUT their id back marking it as available for subsequent use as it may not actually be terminating (consider a case calling recursive bu_parallels() in a loop) |
| 17:27.06 | Notify | 03BRL-CAD:vasco_costa * 66076 (brlcad/trunk/src/librt/primitives/common.cl brlcad/trunk/src/librt/primitives/primitive_util.c brlcad/trunk/src/librt/primitives/rt.cl): fix ocl linking errors with amd ocl. |
| 17:27.08 | Notify | 03BRL-CAD:vasco_costa * 66077 brlcad/trunk/src/librt/primitives/primitive_util.c: ocl program loading fixes. |
| 17:27.19 | Notify | 03BRL-CAD:vasco_costa * 66078 (brlcad/trunk/src/librt/primitives/primitive_util.c brlcad/trunk/src/librt/primitives/rt.cl and 3 others): fix ocl color rendering. fix issue when rendering scene with nothing on screen. |
| 17:27.28 | Notify | 03BRL-CAD:vasco_costa * 66079 (brlcad/trunk/src/librt/primitives/primitive_util.c brlcad/trunk/src/librt/primitives/rt.cl): fix whitespace. |
| 17:27.30 | Notify | 03BRL-CAD:vasco_costa * 66080 brlcad/trunk/src/librt/primitives/primitive_util.c: revert improperly applied patch. |
| 17:27.40 | Notify | 03BRL-CAD:vasco_costa * 66081 (brlcad/trunk/src/librt/primitives/bot/bot_shot.cl brlcad/trunk/src/librt/primitives/primitive_util.c brlcad/trunk/src/librt/primitives/rt.cl): ocl color fixes. |
| 17:27.58 | Notify | 03BRL-CAD:vasco_costa * 66082 (brlcad/trunk/src/librt/cut.c brlcad/trunk/src/librt/prep.c and 6 others): improved ocl stats. |
| 17:28.04 | Notify | 03BRL-CAD:vasco_costa * 66083 brlcad/trunk/src/librt/primitives/rt.cl: use pown since exp is int. |
| 17:28.25 | Notify | 03BRL-CAD:brlcad * 66084 brlcad/trunk/src/other/openNURBS/opennurbs_array_defs.h: revert 65966 as casting merely makes the overflow occur silently, badness. |
| 17:28.27 | Notify | 03BRL-CAD:brlcad * 66085 brlcad/trunk/src/other/openNURBS/opennurbs_array_defs.h: avoid signed overflow by subtracting ele_cnt from both sides of the expression. subtraction underflow is okay -- the lesser-than side of the expression goes negative and the expression remains consistent. |
| 17:29.04 | Notify | 03BRL-CAD:vasco_costa * 66086 (brlcad/trunk/src/librt/primitives/primitive_util.c brlcad/trunk/src/librt/primitives/rt.cl): automagically set local workgroup size in ocl kernel launches. gets us like 2x speedup on GTX TITAN. |
| 17:32.09 | Notify | 03BRL-CAD:vasco_costa * 66087 (brlcad/trunk/src/librt/primitives/ehy/ehy_shot.cl brlcad/trunk/src/librt/primitives/primitive_util.c and 3 others): use less memory to store solid ids and materials in ocl. eliminate some more branches and simplify logic in solver. |
| 17:33.10 | Notify | 03BRL-CAD:vasco_costa * 66088 (brlcad/trunk/src/librt/primitives/common.cl brlcad/trunk/src/librt/primitives/solver.cl): eliminate branches from ocl cubic solver code. fix ocl quartic solver code. |
| 17:33.15 | Notify | 03BRL-CAD:vasco_costa * 66089 (brlcad/trunk/src/librt/primitives/common.cl brlcad/trunk/src/librt/primitives/solver.cl): revert ocl cubic solver. |
| 17:33.18 | Notify | 03BRL-CAD:vasco_costa * 66090 (brlcad/trunk/src/librt/primitives/tgc/tgc_shot.cl brlcad/trunk/src/librt/primitives/tor/tor_shot.cl): update ocl tor implementation to look more similar to tgc. |
| 17:34.36 | Notify | 03BRL-CAD Wiki:85.245.48.64 * 9461 /wiki/User:Vasco.costa/GSoC15/logs: /* Week 13 : 17 Aug-23 Aug */ |
| 17:34.38 | Notify | 03BRL-CAD Wiki:85.245.48.64 * 9462 /wiki/User:Vasco.costa/GSoC15/logs: /* Week 13 : 17 Aug-23 Aug */ |
| 17:34.40 | Notify | 03BRL-CAD Wiki:Vasco.costa * 0 /wiki/File:Cl_golliath.png: |
| 17:34.42 | Notify | 03BRL-CAD Wiki:Vasco.costa * 9464 /wiki/User:Vasco.costa/GSoC15/logs: /* Week 13 : 17 Aug-23 Aug */ |
| 17:34.45 | Notify | 03BRL-CAD Wiki:Vasco.costa * 9465 /wiki/User:Vasco.costa/GSoC15/logs: /* Week 13 : 17 Aug-23 Aug */ |
| 17:34.47 | Notify | 03BRL-CAD Wiki:Vasco.costa * 9466 /wiki/User:Vasco.costa/GSoC15/logs: /* Week 12 : 10 Aug-16 Aug */ |
| 17:34.49 | Notify | 03BRL-CAD Wiki:Vasco.costa * 9467 /wiki/User:Vasco.costa/GSoC15/logs: /* Development Status */ |
| 17:34.52 | Notify | 03BRL-CAD Wiki:Vasco.costa * 9468 /wiki/User:Vasco.costa/GSoC15/logs: /* Week 13 : 17 Aug-23 Aug */ |
| 17:34.53 | Notify | 03BRL-CAD Wiki:Vasco.costa * 9469 /wiki/User:Vasco.costa/GSoC15/logs: /* Week 13 : 17 Aug-23 Aug */ |
| 17:34.55 | Notify | 03BRL-CAD Wiki:Vasco.costa * 9470 /wiki/User:Vasco.costa/GSoC15/logs: /* Week 13 : 17 Aug-23 Aug */ |
| 17:35.01 | Notify | 03BRL-CAD Wiki:Vasco.costa * 9471 /wiki/User:Vasco.costa/GSoC15/logs: /* Week 13 : 17 Aug-23 Aug */ |
| 17:35.01 | Notify | 03BRL-CAD Wiki:Vasco.costa * 9472 /wiki/User:Vasco.costa/GSoC15/logs: /* Week 13 : 17 Aug-23 Aug */ |
| 17:35.01 | Notify | 03BRL-CAD Wiki:Vasco.costa * 9473 /wiki/User:Vasco.costa/GSoC15/logs: /* Week 12 : 10 Aug-16 Aug */ |
| 17:35.03 | Notify | 03BRL-CAD Wiki:Gurwinder Singh * 9474 /wiki/User:Gurwinder_Singh/GSoc15/log_developmen: |
| 17:35.05 | Notify | 03BRL-CAD Wiki:Vasco.costa * 9475 /wiki/User:Vasco.costa/GSoC15/logs: /* Week 13 : 17 Aug-23 Aug */ |
| 17:35.07 | Notify | 03BRL-CAD Wiki:Saaj brlcad * 0 /wiki/User:Saaj_brlcad: |
| 17:35.09 | Notify | 03BRL-CAD Wiki:Einsteinjunior * 0 /wiki/User:Einsteinjunior: |
| 17:35.11 | Notify | 03BRL-CAD Wiki:FrankBirdsong * 0 /wiki/User:FrankBirdsong: |
| 17:35.13 | Notify | 03BRL-CAD Wiki:Vasco.costa * 9476 /wiki/User:Vasco.costa/GSoC15/logs: /* Development Status */ |
| 17:35.15 | Notify | 03BRL-CAD Wiki:Vasco.costa * 9477 /wiki/User:Vasco.costa/GSoC15/logs: /* Week 13 : 17 Aug-23 Aug */ |
| 17:35.17 | Notify | 03BRL-CAD Wiki:Vasco.costa * 9478 /wiki/User:Vasco.costa/GSoC15/logs: /* Week 13 : 17 Aug-23 Aug */ |
| 17:35.19 | Notify | 03BRL-CAD Wiki:Vasco.costa * 9479 /wiki/User:Vasco.costa/GSoC15/logs: /* Week 13 : 17 Aug-23 Aug */ |
| 17:35.21 | Notify | 03BRL-CAD Wiki:Vasco.costa * 9480 /wiki/User:Vasco.costa/GSoC15/logs: /* Week 13 : 17 Aug-23 Aug */ |
| 17:35.23 | Notify | 03BRL-CAD Wiki:Gurwinder Singh * 9481 /wiki/User:Gurwinder_Singh/GSoc15/log_developmen: |
| 17:35.25 | Notify | 03BRL-CAD Wiki:Liitmyalit * 0 /wiki/User:Liitmyali: |
| 17:35.27 | Notify | 03BRL-CAD Wiki:Gurwinder Singh * 9482 /wiki/User:Gurwinder_Singh/GSoc15/log_developmen: |
| 17:35.29 | Notify | 03BRL-CAD Wiki:Zeno . X . * 0 /wiki/User:Zeno_._X_.: |
| 18:01.33 | *** join/#brlcad ries (~ries@D979C47E.cm-3-2d.dynamic.ziggo.nl) | |
| 18:03.58 | *** join/#brlcad sofat (~sofat@202.164.45.212) | |
| 18:06.04 | sofat | starseeker, I am facing this error in resource how I solve this ".txt |
| 18:06.05 | sofat | <vasc> actually this is the syntax |
| 18:06.05 | sofat | <sofat_> ok |
| 18:06.05 | sofat | <vasc> iso-8859-15 is same thing as iso-8859-1 except it has the euro sign () in it |
| 18:06.05 | sofat | <sofat_> hmm |
| 18:06.05 | sofat | <vasc> you can use either and it should work |
| 18:06.07 | sofat | <vasc> prolly |
| 18:06.09 | sofat | <sofat_> how i tell these reasons to brlcad |
| 18:06.11 | sofat | <vasc> beats me. i don't know what's his problem |
| 18:06.13 | sofat | <vasc> can only guess |
| 18:06.17 | sofat | <sofat_> ok |
| 18:06.19 | sofat | * Disconnected (Connection reset by peer)." |
| 18:06.48 | *** join/#brlcad sofat (~sofat@202.164.45.212) | |
| 18:07.06 | sofat | " CMake Error: Parse error in cache file /home/nouhrasofat/brlcad/CMakeCache.txt. Offending entry: We cannot execute java" |
| 18:15.17 | vasc | ok, just wasted 6 hours of my time trying to put the aila & laine renderer in our code |
| 18:15.26 | vasc | i.e. the traversal |
| 18:15.28 | vasc | it's SLOWER |
| 18:16.21 | vasc | how awfully gratifying that was |
| 18:17.16 | vasc | so much for dynamic ray fetching |
| 18:17.49 | vasc | just breaking it into small tiles does the trick |
| 18:17.58 | vasc | and its TWO lines of code |
| 18:17.59 | Stragus | Dynamic ray fetching? That sounds like a bad idea |
| 18:18.00 | vasc | maybe THREE |
| 18:18.12 | vasc | not all rays have same length right. so |
| 18:18.29 | Stragus | There are always academics claiming about some fancy new idea like runtime ray sorting, dynamic whatever |
| 18:18.32 | vasc | maybe this thread ended and you want it to pick something else before the whole workgroup finishes too |
| 18:18.46 | Stragus | Yes, and it becomes totally incoherent |
| 18:18.51 | Stragus | Therefore, bad idea |
| 18:22.10 | vasc | exactly |
| 18:22.25 | vasc | well i didn't reorder the rays in z-order first |
| 18:22.42 | vasc | and it was almost as fast as our current code once i change some parameters |
| 18:22.43 | vasc | almost |
| 18:22.51 | vasc | but it needed PTX instructions for that |
| 18:22.55 | Stragus | Don't believe what the papers say, and feel free to bounce ideas with me about raytracing |
| 18:23.17 | vasc | well it was a ... highly celebrated paper |
| 18:23.25 | Stragus | Your coherent rays should be much faster |
| 18:23.36 | Stragus | Do you any kind of voting before intersecting primitives? |
| 18:23.44 | vasc | i just split the screen into 8x8 tiles and blammo |
| 18:23.51 | vasc | no |
| 18:24.00 | Stragus | "At least N of all threads in warp wants to intersect, therefore we go in, otherwise wait" |
| 18:24.03 | vasc | that other code did that |
| 18:24.24 | vasc | i think i'll store the patch in the bug tracker just in case |
| 18:31.03 | vasc | https://sourceforge.net/p/brlcad/patches/416/ |
| 18:31.07 | vasc | in case you are interested |
| 18:36.45 | vasc | i'm tired |
| 18:36.58 | vasc | i want to make it even faster but other than the 8x8 subblocks i'm stumped |
| 18:37.07 | vasc | i shrank some data structures |
| 18:37.10 | vasc | that was about it |
| 18:37.18 | Stragus | Ah optimization, the fun part |
| 18:37.25 | Stragus | (No sarcasm, I love optimization) |
| 18:38.07 | Stragus | Did you make sure all reads/stores are coherent, if rays are also coherent? |
| 18:38.16 | Stragus | Warp voting before intersection would be a good idea |
| 18:38.42 | vasc | right. that OTHER patch did that |
| 18:38.44 | Stragus | Branch merging too |
| 18:38.54 | vasc | uses PTX instructions |
| 18:39.03 | Stragus | Yes well, without any dynamic fetch garbage |
| 18:39.13 | vasc | the rays are primary rays right now and i'm using 8x8 bundles |
| 18:39.14 | Stragus | I don't think they want any assembly in there... |
| 18:39.18 | vasc | so i would say they are coherent |
| 18:39.39 | Stragus | What do the memory write patterns look like? |
| 18:39.56 | vasc | well we have a couple of read and write pattern issues |
| 18:40.01 | Stragus | Does each thread N always write results to some array[N]? |
| 18:40.11 | vasc | the bvh is in one piece of memory, the objects data in another |
| 18:40.11 | Stragus | And not array[N*foo+something] |
| 18:40.18 | vasc | and the image is not stored in z-order |
| 18:40.38 | Stragus | Memory access patterns are critical for GPU optimization |
| 18:41.01 | Stragus | And proper use of the shared memory, *NOT* global memory for any kind of temporary results or data |
| 18:41.01 | vasc | the thing is i could use a regular clImage and it would do it for me |
| 18:41.14 | vasc | but then we can't use that clImage data on the backend |
| 18:41.38 | vasc | we would have to change format from RGBA8 to RGB8DEPTHBE64 |
| 18:42.10 | vasc | unless we rewrite the whole backend |
| 18:42.17 | vasc | with all its multiple render targets |
| 18:42.33 | *** join/#brlcad bhollister (~brad@2601:647:cb01:9750:5c7a:866:4799:eae) | |
| 18:42.34 | vasc | like a dozen of them |
| 18:43.44 | vasc | well the hit point lists are in global memory right now |
| 18:43.59 | Stragus | There, that's a major bottleneck to fix |
| 18:44.14 | Stragus | Far more critical than dynamic ray whatever |
| 18:44.17 | vasc | i don't wanna change that until i figure out which algorithm i wanna use |
| 18:44.22 | vasc | peeling or whatever |
| 18:44.23 | Stragus | Fair point |
| 18:44.43 | vasc | we need something that can do transparent rendering with multi-hits and csg too |
| 18:44.56 | Stragus | Sure |
| 18:45.01 | vasc | i read some paper that claimed you could compute the csg incrementally using two buffers |
| 18:45.09 | vasc | one for the in points another for the out points |
| 18:45.19 | vasc | but i don't remember the reference anymore :-| |
| 18:46.04 | vasc | i think it was 10-20 years olds |
| 18:46.38 | Stragus | Probably not useful for GPU hardware |
| 18:47.17 | vasc | it sound like i could avoid the dual passes with that one |
| 18:47.33 | vasc | i'm doing dual passes now |
| 18:47.55 | vasc | one to count the required memory for the hit point lists |
| 18:48.01 | vasc | and the other to actually store data in them |
| 18:48.17 | vasc | well |
| 18:48.24 | vasc | maybe i'll come up with something |
| 18:48.29 | Stragus | I told you, giant static buffer of "bundles" of N hits, allocated through multiple atomics |
| 18:48.38 | Stragus | Single pass, pretty efficient |
| 18:48.47 | vasc | is it |
| 18:48.59 | vasc | it kinda doesn't pass my smell test |
| 18:49.06 | Stragus | You could even make the writes coherent by always allocating N hits for all rays of the warp |
| 18:49.13 | vasc | something tells me i can do it incrementally with a couple of static buffers |
| 18:49.16 | Stragus | You don't allocate every single hit, you allocate bundles |
| 18:50.03 | Stragus | The other, better solution is buffering all hits in shared memory and resolving the segments right there |
| 18:50.10 | vasc | e.g. the way i do the multi-hit transparency right |
| 18:50.13 | vasc | i traverse in depth order |
| 18:50.16 | vasc | and add colors up |
| 18:50.29 | vasc | it accumulates the colors |
| 18:51.14 | vasc | there's nothing preventing me doing the traversal in reverse depth order... except... |
| 18:51.24 | Stragus | Reverse depth order? Why?... |
| 18:51.34 | vasc | well then |
| 18:51.37 | vasc | even then |
| 18:51.42 | Stragus | Front-to-back is the only way that makes sense, especially if you want to be able to terminate rays early |
| 18:51.52 | vasc | basically that color computation is essentially a huge scan operation |
| 18:52.32 | vasc | which i am doing linearly right |
| 18:52.40 | vasc | i know scan operations like that can be done much faster |
| 18:52.57 | Stragus | In my raytracer's inlined callbacks, I accumulate colors in plain *registers*, then in the Final() inlined callback, I write the final color to global memory just once |
| 18:53.18 | vasc | that's what i'm doing now |
| 18:53.29 | Stragus | Okay good, I understood something else |
| 18:53.30 | vasc | but it also means you're using a single thread to do that accumulation |
| 18:53.42 | Stragus | Each thread accumulate its own ray, yes?... |
| 18:53.46 | vasc | yes |
| 18:54.20 | Stragus | I don't see where the scan operation comes in |
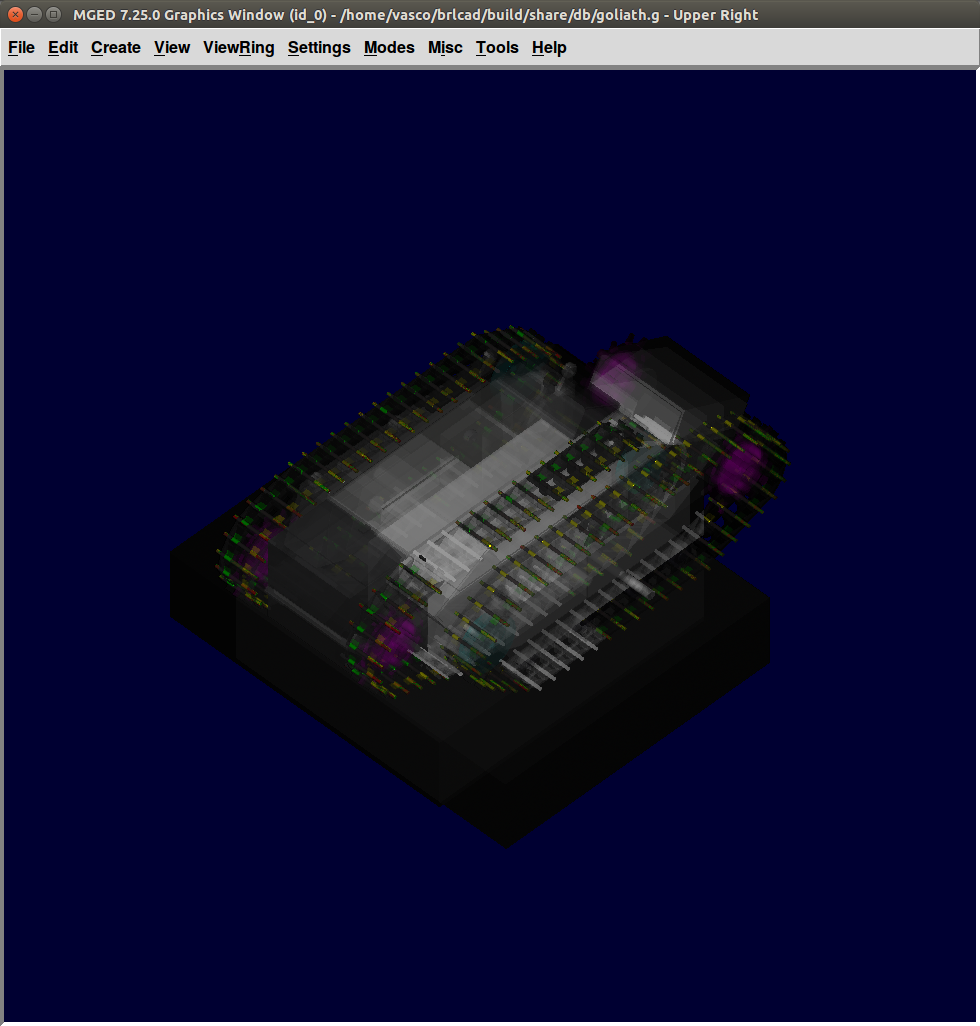
| 18:54.36 | vasc | http://brlcad.org/w/images/7/7d/Cl_golliath.png |
| 18:54.40 | vasc | multi-hit goliath |
| 18:55.08 | vasc | just summing the color contributions along the ray points |
| 18:55.15 | vasc | i think i'm doing something wrong there but... |
| 18:55.27 | Stragus | Can't you do that just as hits are produced? |
| 18:55.44 | vasc | no because its transparent |
| 18:55.49 | Stragus | And?... |
| 18:56.06 | vasc | it would have to be processed front to back |
| 18:56.19 | Stragus | That's not the way rays are traced? |
| 18:56.19 | vasc | or it would look bad |
| 18:56.28 | vasc | rays are processed recursively |
| 18:56.31 | vasc | i trace one ray |
| 18:56.34 | vasc | hit a surface |
| 18:56.37 | vasc | trace another ray |
| 18:56.39 | vasc | and so on |
| 18:56.43 | vasc | then i add the contributions |
| 18:56.52 | vasc | it does the last piece first |
| 18:56.54 | vasc | get it |
| 18:57.18 | Stragus | That implies you have to buffer everything |
| 18:57.26 | vasc | in here i'm cheating coz i'm not doing snell's law of anything |
| 18:57.36 | vasc | i just shoot one ray and it always goes straight |
| 18:57.38 | vasc | nyayaya |
| 18:57.46 | Stragus | That's what raytracers do :p |
| 18:57.56 | vasc | not physically based ones |
| 18:57.57 | Stragus | If someone wants a ray that bends direction, he'll shoot a new ray |
| 18:58.07 | vasc | exactly |
| 18:58.22 | Stragus | Actually, my raytracer can handle a new direction vector from within the hit() callback, but let's not go there |
| 18:58.24 | vasc | this one goes straight through the entire scene. thought things too |
| 18:58.29 | Stragus | Right |
| 18:58.40 | vasc | its just to make pretty pictures |
| 18:58.46 | vasc | kind like fake translucency |
| 18:59.01 | vasc | actually its translucency where there is no reflected part of the ray |
| 18:59.04 | vasc | it goes all in |
| 18:59.17 | vasc | i mean |
| 18:59.38 | vasc | both angles on snell's law are the asme |
| 18:59.41 | vasc | same |
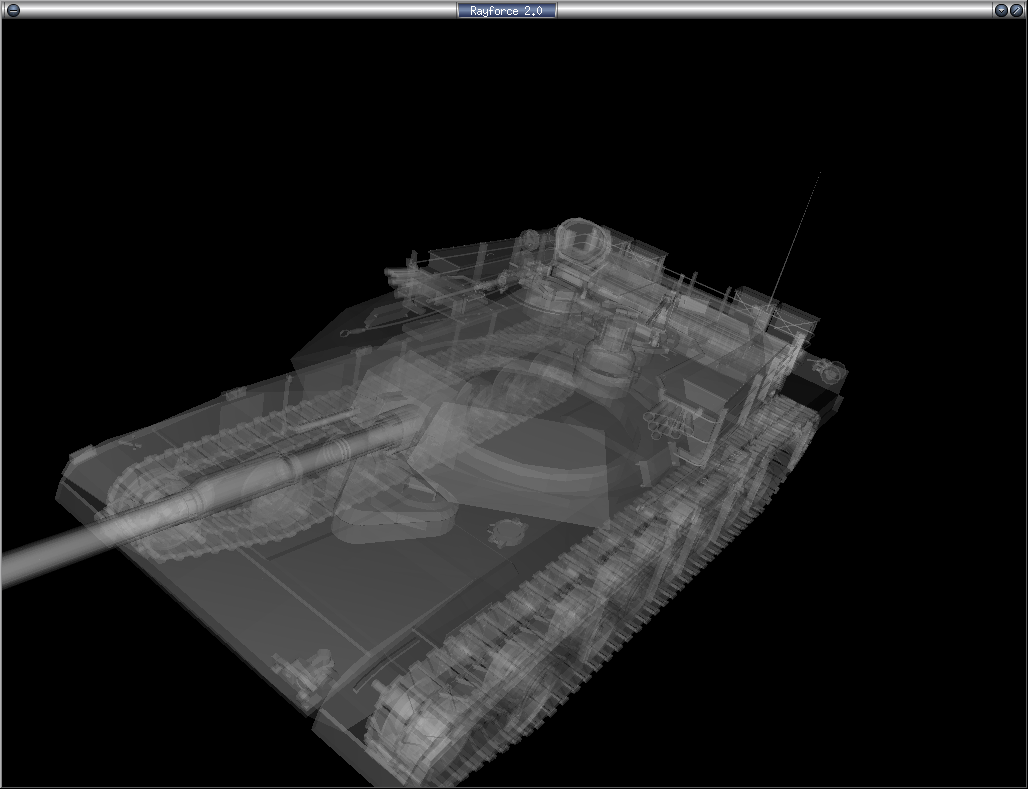
| 18:59.54 | Stragus | My multi-hits: http://www.rayforce.net/rfmultihits.png |
| 19:00.02 | Stragus | I know what it is :p |
| 19:00.06 | vasc | cute |
| 19:00.31 | vasc | so do you do it back to front of what? |
| 19:00.45 | vasc | i guess i need to read the depth peeling paper again |
| 19:00.51 | Stragus | Front to back, hits are processed as they come, *nothing* is buffered, no memory is ever written until the end: the final pixel color |
| 19:01.08 | Stragus | Depth peeling is terrible |
| 19:01.17 | vasc | Depth peeling works by rendering the image multiple times.[1] The twist is that depth peeling uses two Z buffers, one that works conventionally, and one that is not modified, and sets the minimum distance at which a fragment can be drawn without being discarded. For each pass, the previous pass' conventional Z-buffer is used as the minimal Z-buffer, so each pass draws what was "behind" the previous pass. The resulting images can be combined to form |
| 19:01.18 | vasc | <PROTECTED> |
| 19:01.28 | Stragus | Bad, bad bad |
| 19:01.49 | vasc | man but you can't do it front to back |
| 19:01.51 | Stragus | Trace the rays *once* |
| 19:01.56 | vasc | the transparency will look wrong |
| 19:02.01 | Stragus | No! |
| 19:02.18 | Stragus | First hit, accumulate color, reduce the ray's intensity for the following hits |
| 19:02.26 | Stragus | Like... reduce ray intensity by 0.8 for each hit |
| 19:02.36 | vasc | hm i see |
| 19:03.06 | vasc | i guess i could do that |
| 19:03.08 | Stragus | Doing it that way, you can also cut off rays when they are too "weak" |
| 19:03.23 | Stragus | Which is very similar to bullets shooting through geometry, they have no energy left and you can cut them off |
| 19:04.08 | Stragus | It is highly efficient, I'm talking about 500 million rays per second in that scene |
| 19:04.16 | vasc | so i don't need two passes for multi-hit |
| 19:04.17 | vasc | great |
| 19:04.38 | Stragus | Absolutely no need for multiple passes, and depth peeling is absurd |
| 19:04.48 | vasc | now the question is csg |
| 19:05.19 | Stragus | Right, that is more complex. Temporary hits may have to be stored in shared memory to recompose the proper "segments", or whatever terminology is used |
| 19:05.46 | vasc | i think they call them segments in BRL-CAD |
| 19:05.56 | Stragus | Okay, I wasn't sure |
| 19:05.56 | vasc | a segment has an 'in' and 'out' hit point |
| 19:06.00 | Stragus | Right |
| 19:06.07 | vasc | papers call those surfels or seomthing |
| 19:06.16 | vasc | something |
| 19:10.09 | vasc | http://i.imgur.com/YwIBlpt.png |
| 19:11.44 | Stragus | You should be able to buffer and work on all that in shared memory |
| 19:11.57 | Stragus | If it doesn't fit, it gets a little more complicated |
| 19:14.06 | vasc | the problem is i don't know the size of the list |
| 19:14.11 | vasc | its probably gonna be small but |
| 19:14.16 | vasc | and i need that memory per thread |
| 19:16.11 | Stragus | Right, it needs to be able to extend storage to global memory in the worst case |
| 19:16.34 | Stragus | Which get messy... but the vast majority of cases will be very efficient |
| 19:46.36 | vasc | hm |
| 19:46.39 | vasc | on second thought |
| 19:46.53 | vasc | it still won't work |
| 19:47.04 | vasc | let's say i have the hit callback right |
| 19:47.08 | vasc | it gets called on each hit |
| 19:47.31 | vasc | unless you attenuate with distance... |
| 19:47.35 | vasc | was that it? |
| 19:56.44 | *** join/#brlcad ries (~ries@D979C47E.cm-3-2d.dynamic.ziggo.nl) | |
| 20:05.10 | vasc | any good absorbency functions? |
| 20:05.21 | vasc | i'm trying dist, dist*dist, dist*dist+dist |
| 20:10.23 | Stragus | That doesn't sound right |
| 20:10.50 | Stragus | If you only want to register hits with surfaces, then reduce by 0.8 or so the ray's intensity every hit |
| 20:11.45 | Stragus | If you want to compute absorption within a material, then it's some exp() funtion |
| 20:19.01 | vasc | the hits won't be in order |
| 20:20.47 | vasc | let's say you are processing hits on a cell. the hits on the cell may be out of order |
| 20:20.52 | vasc | even bounding boxes can overlap |
| 20:21.09 | vasc | so even the 2nd processed bounding box may end up having a closer hit |
| 20:21.48 | *** join/#brlcad Izakey (~Izakey@41.205.22.46) | |
| 20:22.19 | Stragus | Ah yes, that's the issue with objet-based partitionning |
| 20:22.31 | Stragus | Then you have to buffer hits in shared memory and reorder |
| 20:23.04 | Stragus | When you know, during the traversal, that new hits won't appear before existing hits, then you can sort the buffered hits and process them right away |
| 20:23.04 | vasc | the log() and pow() seem to work |
| 20:23.29 | Stragus | Uh, okay... not sure why you would need that |
| 20:23.47 | Stragus | Absorption through a transparent material is based on exp(), if that's what you are doing |
| 20:24.13 | vasc | uh |
| 20:24.15 | vasc | forget it |
| 20:26.05 | vasc | the exp grows too fast |
| 20:26.23 | vasc | adjusting |
| 20:26.48 | Stragus | exp( -distance / opacity ); ? |
| 20:27.03 | Stragus | has no idea what you are doing |
| 20:29.06 | vasc | yeah i'm trying that now |
| 20:31.02 | vasc | it looks ok but similar to 1.0/(distance*distance) right now |
| 20:31.32 | Stragus | Well, that isn't physically correct |
| 20:32.30 | Stragus | did some of that absorption stuff in radiation raytracing for fire simulation in computational fluid dynamics |
| 20:36.46 | vasc | well even 1.0/dist looks ok |
| 20:37.41 | vasc | we use that for atmospheric attenuation in ray tracing |
| 20:38.00 | vasc | you just need a smooth function that falls off with distance |
| 20:38.55 | Stragus | exp() is the correct one |
| 20:39.02 | Stragus | Anything else is an approximation just to look okay |
| 20:39.12 | vasc | i guess i'll use that then |
| 20:39.44 | Stragus | Approximate CUDA exp() is pretty fast |
| 20:39.51 | Stragus | Err, OpenCL exp(), same thing |
| 20:40.16 | vasc | <PROTECTED> |
| 20:40.16 | vasc | <PROTECTED> |
| 20:40.16 | vasc | <PROTECTED> |
| 20:40.16 | vasc | <PROTECTED> |
| 20:40.19 | vasc | <PROTECTED> |
| 20:41.45 | vasc | that can be done cummulatively |
| 20:41.59 | vasc | ain't done now coz the callback doesn't have the data pointers to materials and stuff but can be done |
| 20:42.07 | vasc | http://i.imgur.com/cu0xPXt.png |
| 20:42.16 | vasc | vs my old one using ray-tracing method |
| 20:42.34 | vasc | http://brlcad.org/w/images/7/7d/Cl_golliath.png |
| 20:42.42 | vasc | i like old one better even if its two pass... |
| 20:43.11 | Stragus | Always prefer the correct method, this is physics :p |
| 20:43.31 | vasc | light makes rightr |
| 20:43.50 | vasc | you can see more detail on yours though |
| 20:46.15 | vasc | now the question is how to compute the opacity |
| 20:46.17 | vasc | maybe user slider |
| 20:47.58 | vasc | anyway once i integrate this into one pass function |
| 20:48.10 | vasc | then it will work with one pass |
| 20:48.27 | vasc | some more trashing though |
| 20:48.53 | vasc | to load materials and crap |
| 20:50.18 | vasc | kewl thanks |
| 20:50.46 | vasc | another essential mode that doesn't need multiple passes |
| 20:50.56 | Stragus | Good :) |
| 20:53.57 | vasc | the distance should probably the converted into world box coordinates or something |
| 20:54.01 | vasc | ah ewll |
| 20:54.26 | vasc | its a matter of fudging |
| 20:54.48 | vasc | the attenuation needs to take into account the model |
| 20:54.49 | Stragus | Opacity per meter should be defined somewhere |
| 20:54.57 | vasc | hm ok |
| 20:55.40 | vasc | now the other question is should i only be doing this for the IN points |
| 20:55.45 | vasc | and not the OUT points... |
| 20:55.47 | vasc | eheh |
| 20:55.55 | *** join/#brlcad ih8sum3r (~ih8sum3r@122.173.189.145) | |
| 20:57.04 | Stragus | Opacity is a function of distrance travelled between in and out? |
| 20:57.18 | Stragus | distance* too |
| 20:57.41 | vasc | ohhhh. ... that's messed up |
| 20:57.45 | vasc | but not impossible actually |
| 20:58.02 | Stragus | If you just want to show surfaces, then accumulate all hits, reduce ray intensity every hit |
| 20:58.15 | vasc | like i said they aren't ordered |
| 20:58.31 | Stragus | [...] accumulate all sorted hits [...] |
| 21:00.30 | vasc | i'll think about it a bit |
| 21:01.05 | vasc | so its exp(-hit_dist*1e-3)*length_segment? |
| 21:06.07 | vasc | that doesn't look so good |
| 21:14.13 | vasc | aw the first one is ok |
| 22:01.06 | Stragus | vasc, it's exp( -SegmentLength * opacity ); |
| 22:01.15 | Stragus | It's / opacity depending on your units |
| 22:01.47 | Stragus | It's the energy absorption of the ray for some given distance through some opaque material |
| 22:02.26 | Stragus | You still need to go front-to-back and reduce the ray's energy as it traverses material, each loss of energy gives a color depending on the material |
| 22:03.48 | vasc | gah |
| 22:04.54 | vasc | that bytes |
| 22:05.00 | vasc | you can't do that without two passes |
| 22:05.07 | vasc | you need an ordered list of hits |
| 22:05.27 | vasc | bites |
| 22:10.33 | vasc | even with the ordered list its a pain |
| 22:11.05 | vasc | its like you get out a primitive into air |
| 22:11.10 | vasc | and then into a primitive again |
| 22:11.16 | vasc | and inside a primitive that's inside another |
| 22:11.19 | vasc | and they cross |
| 22:11.22 | vasc | and whatever |
| 22:13.01 | vasc | man i found this guy's phd thesis |
| 22:13.09 | vasc | he's went overboard on the topic |
| 22:13.11 | vasc | i'll skim it |
| 22:13.14 | vasc | csg |
| 22:14.47 | Stragus | You buffer all hits in shared memory, as soon as you know any new hit will *not* occur before existing buffered hits, you process all these hits and flush the buffer |
| 22:15.18 | Stragus | With the buffered hits, you can determine entry/exit points and build the segments |
| 22:16.12 | *** join/#brlcad bhollister (~brad@2601:647:cb01:9750:7d54:b79d:72f2:3078) | |
| 22:17.11 | vasc | it's messed up |
| 22:17.22 | vasc | coz i don't know if i'll overflow until i process a primitive |
| 22:17.31 | vasc | and if i do it in the middle i'll have to backtrack |
| 22:17.33 | vasc | and its a mess |
| 22:17.36 | vasc | don't wanna do it |
| 22:17.45 | vasc | i think there is a better option |
| 22:17.58 | vasc | the buffer thing |
| 22:18.22 | vasc | but i'm reading more |
| 22:18.44 | Stragus | The hit buffering can technically overflow... but darn, shoot small packets of rays with a huge static chunk of global memory to allocate on-demand, the risk is very low |
| 22:18.46 | vasc | Near real-time CSG rendering using tree normalization and geometric pruning |
| 22:19.02 | Stragus | And if it *does* happen, you break the packet into smaller bundles of rays and try again |
| 22:19.34 | Stragus | The good answers don't have to be in papers, you know :p |
| 22:19.48 | vasc | "Near real-time CSG rendering using tree normalization and geometric pruning" |
| 22:19.51 | Stragus | Though I certainly recognize you are from academia, eh |
| 22:19.54 | vasc | dude |
| 22:20.02 | vasc | i had the gut feeling it could be done |
| 22:20.14 | vasc | with something other than storing the whole list somewhere |
| 22:20.18 | vasc | in an incremental fashion |
| 22:20.23 | vasc | so i searched and searched |
| 22:20.30 | vasc | and found TWO papers that already do that |
| 22:20.58 | vasc | it's the XXIst century. everyone is bound to have thought of a way to do it yet |
| 22:21.02 | vasc | even if it SUCKS |
| 22:21.13 | vasc | :-D |
| 22:21.34 | Stragus | Sometimes. And not everyone bothers writing papers about it, and a lot of people needs to write papers, even if filled with garbage, to fill their quotas |
| 22:21.55 | vasc | that too |
| 22:22.08 | vasc | see i have to write mine |
| 22:22.30 | vasc | i'm just concerned if the buffering approach is prone to errors or not |
| 22:22.36 | vasc | such approaches usually are |
| 22:22.52 | vasc | so i've been reading everything else |
| 22:23.03 | vasc | including this reconfigurable hardware system some japanese made in the 1970d |
| 22:23.08 | vasc | that bad |
| 22:23.09 | Stragus | Errors like what? |
| 22:23.23 | vasc | you know like z-shit |
| 22:23.31 | vasc | things in wrong order |
| 22:23.33 | vasc | crap like thart |
| 22:23.49 | Stragus | If the hits don't fit in the memory allocated, you bail out, the CPU C code detects the error condition, it breaks the packet of rays into smaller independant bundles and try again |
| 22:24.07 | vasc | man |
| 22:24.13 | vasc | that's like calling a syscalls |
| 22:24.15 | vasc | from the gpu |
| 22:24.22 | vasc | it's what i want to avoid |
| 22:24.23 | Stragus | The probability of this happening is **very** low |
| 22:24.31 | vasc | famous last words |
| 22:24.43 | Stragus | But it might still happen, so that's why you have code to handle it |
| 22:24.45 | vasc | that reminds me of located |
| 22:25.24 | vasc | man if i wasn't interested in understanding the actual problem |
| 22:25.35 | vasc | instead of reading this phd thesis of this guy and all this crap |
| 22:25.39 | Stragus | If it happens just once, you know that the heuristics used for hits/ray have to be revised in this particular scene, for future raytracing operations |
| 22:25.44 | vasc | i would just get the rossignac paper and implement that |
| 22:26.52 | vasc | from what i get the rossignac paper is that goldfeather paper with more pizzaz |
| 22:27.12 | vasc | 20 years of hindsight |
| 22:27.32 | vasc | i'll just continue reading about csg |
| 22:27.38 | vasc | in this hundreds of pages this |
| 22:27.40 | Stragus | I have no idea about these papers... I just think I know both raytracing and CUDA, and I feel like I very much see what the best solution is |
| 22:27.40 | vasc | thesis |
| 22:28.03 | vasc | i used to want to be an historian before i went into computer engineering |
| 22:28.10 | vasc | so i dig this stuff |
| 22:28.14 | Stragus | Eh, all right then |
| 22:28.21 | vasc | seeing the path others have throdden and failed and so on |
| 22:28.45 | Stragus | I don't like reading papers, it ruins the fun of figuring things out and, worst of all, it contaminates the thought process to figure out new solutions |
| 22:33.04 | vasc | see that's the thing |
| 22:33.18 | vasc | there's beauty not only in the discovery but in the travel as well |
| 22:33.37 | vasc | it's like when i saw The Lord of the Rings in Movie form even though I already had read the books and knew the story |
| 22:36.05 | Stragus | For some, the travel can be sitting in front of black sheets of paper for hours, eh |
| 22:36.11 | Stragus | of blank* sheets |
| 22:37.06 | Stragus | I quite enjoy that actually, sometimes the solution turns out better than the existing ones, sometimes it's already out there. But it was more fun either way |
| 22:38.10 | vasc | i've done the opposite too |
| 22:38.18 | vasc | start blank sheet and work on it for 2-3 months |
| 22:38.27 | vasc | then i realize its all in a 15 year old paper |
| 22:38.40 | vasc | i work on it another 2 months and its state of the art paper |
| 22:39.01 | vasc | both approaches are ok |
| 22:46.16 | vasc | that was some long 111 pages |
| 22:46.18 | vasc | next |
| 22:46.57 | Stragus | How many lines of it were interesting? :p |
| 22:47.44 | vasc | about 5-6 pages |
| 22:48.15 | vasc | it was good enough to make me realize the problem is more complicated than i thought it was |
| 22:48.37 | vasc | i.e. how to map that CSG tree to the points |
| 22:49.05 | vasc | and how to evaluate a tree like that efficiently |
| 22:49.30 | vasc | it went into these bit coding schemes but i kinda didn't read it |
| 22:57.26 | vasc | this 2011 paper sounds familiar . he's doing the same as me. counting the sizes of the lists in a first pass, doing a scan, and allocating the buffer to fill them next |
| 22:57.28 | vasc | herp derp |
| 22:58.02 | vasc | he even uses small list sorting. just like we do. herp derp |
| 22:58.25 | vasc | except he uses shell sort i think we use intersection sort |
| 22:58.30 | vasc | gotta try something else |
| 22:58.46 | vasc | maybe bubblesort |
| 23:02.31 | vasc | yeah the old bubblesort. gotta try that one |
| 23:02.40 | vasc | nothing better to sort already sorted lists. its optimal |
| 23:09.51 | vasc | that's was kind of fun seeing another guy doing the same |
| 23:10.09 | vasc | of course he didn't bother mentioning the problems i actually have left to solve. fegh. |
| 23:21.06 | Stragus | Papers often do that. They present a technique, and completely omit discussing the serious problems and issues of the technique |
| 23:31.18 | vasc | ok |
| 23:31.44 | vasc | so at least the old style buffer techniques have the issue that for convex primitives (think tgc) you need multiple passes |
| 23:31.51 | vasc | the more convex the more passes |
| 23:31.58 | vasc | i mean concave |
| 23:32.43 | *** join/#brlcad merzo (~merzo@85-7-133-95.pool.ukrtel.net) | |
| 23:32.50 | vasc | e.g. for the torus it would require two passes |
| 23:33.01 | vasc | that's what they mean by n-convex |
| 23:33.22 | vasc | the number of in-out pairs a ray can pass most through a primitive |
| 23:33.40 | vasc | so it's a least two passes |
| 23:34.09 | vasc | we can compute the number of passes in runtime |
| 23:34.21 | vasc | just check the number of hits per primitive we intersect |
| 23:34.25 | vasc | and divide by two |
| 23:34.51 | vasc | the max for all those primitives is the number of buffer passes |
| 23:35.35 | vasc | using the goldfeather algorithm, |
| 23:36.10 | vasc | i saw nothing about transparency too |
| 23:36.15 | vasc | i think its done for opaque |
| 23:36.19 | vasc | but its 1989 |
| 23:37.10 | vasc | now this century |
| 23:37.20 | vasc | btw |
| 23:37.34 | vasc | it required two z-buffers and 3 bits buffers |
| 23:37.47 | vasc | we can have all the buffers we wnt |
| 23:38.04 | vasc | its not like we are limited to kludges to use the opengl buffer like those other guys |
| 23:38.14 | vasc | from the late 1990s early 2000s |
| 23:38.27 | vasc | so i'll ignore those for most part |
{kind=link}
{kind=link}
{kind=link}
{kind=link}