| 00:13.13 | *** join/#brlcad scqdzsqsugpfvsyk (~armin@dslc-082-083-184-129.pools.arcor-ip.net) | |
| 00:21.08 | *** join/#brlcad infobot (ibot@rikers.org) | |
| 00:21.08 | *** topic/#brlcad is GSoC students: if you have a question, ask and wait for an answer ... responses may take minutes or hours. Ask and WAIT. ;) | |
| 01:06.38 | *** join/#brlcad teepee (~teepee@unaffiliated/teepee) | |
| 01:10.25 | *** join/#brlcad DaRock (~Thunderbi@mail.unitedinsong.com.au) | |
| 03:23.46 | *** join/#brlcad kintel (~kintel@unaffiliated/kintel) | |
| 03:24.36 | *** join/#brlcad kintel (~kintel@unaffiliated/kintel) | |
| 03:25.26 | *** join/#brlcad kintel (~kintel@unaffiliated/kintel) | |
| 03:26.11 | *** join/#brlcad kintel (~kintel@unaffiliated/kintel) | |
| 03:27.01 | *** join/#brlcad kintel (~kintel@unaffiliated/kintel) | |
| 03:27.51 | *** join/#brlcad kintel (~kintel@unaffiliated/kintel) | |
| 03:28.36 | *** join/#brlcad kintel (~kintel@unaffiliated/kintel) | |
| 03:29.26 | *** join/#brlcad kintel (~kintel@unaffiliated/kintel) | |
| 03:30.11 | *** join/#brlcad kintel (~kintel@unaffiliated/kintel) | |
| 03:40.21 | *** join/#brlcad teepee_ (~teepee@unaffiliated/teepee) | |
| 06:50.13 | *** join/#brlcad inxirwtrrrpwmydy (~armin@dslc-082-083-184-129.pools.arcor-ip.net) | |
| 07:26.15 | *** join/#brlcad Caterpillar (~caterpill@unaffiliated/caterpillar) | |
| 10:43.42 | *** join/#brlcad DaRock (~Thunderbi@mail.unitedinsong.com.au) | |
| 13:08.07 | *** join/#brlcad kintel (~kintel@unaffiliated/kintel) | |
| 13:28.21 | *** join/#brlcad yorik (~yorik@2804:431:f721:94ee:290:f5ff:fedc:3bb2) | |
| 14:04.11 | *** join/#brlcad ``Erik (~erik@pool-100-16-14-17.bltmmd.fios.verizon.net) | |
| 15:33.44 | *** join/#brlcad Caterpillar2 (~caterpill@unaffiliated/caterpillar) | |
| 16:26.18 | *** join/#brlcad d_rossberg (~rossberg@104.225.5.10) | |
| 17:19.19 | *** join/#brlcad KimK (~Kim__@2600:8803:7a81:7400:c1b9:9c23:aaf0:3cf0) | |
| 18:41.23 | Notify | 03BRL-CAD:Marco-domingues * 10018 /wiki/User:Marco-domingues/GSoC17/Log: 5 June |
| 19:23.56 | *** join/#brlcad yorik (~yorik@2804:431:f721:94ee:290:f5ff:fedc:3bb2) | |
| 19:36.42 | *** join/#brlcad LordOfBikes (~armin@dslc-082-083-184-129.pools.arcor-ip.net) | |
| 19:37.50 | *** join/#brlcad vasc (~vasc@bl13-101-248.dsl.telepac.pt) | |
| 19:38.25 | vasc | pokes at mdtwenty[m] |
| 19:50.44 | vasc | there was a site with IRC logs for this channel somewhere. someone got a link to the logs? |
| 20:07.18 | mdtwenty[m] | Hey.. After our conversation last week, i came up with a new solution to the weave_segs kernel. I tried first to implement it without allocating a fixed size array to store the segments in each partition, and although the number of partitions per ray was correct, the segments in each partition were not and the code was a bit messy. So I decided to first implement it with a fixed array of segments in each partition (I |
| 20:07.18 | mdtwenty[m] | started with an array of 100 elements because it was sufficient for the example) and the results seemed ok (i.e the number of partitions and segments in each partition after boolean evaluation seemed correct for the example i am using to test) |
| 20:11.25 | vasc | i don't see how that makes things simpler since it was bounded... but do continue. |
| 20:12.09 | vasc | mdtwenty[m] |
| 20:13.58 | starseeker | Notify: irc |
| 20:14.03 | starseeker | hmm |
| 20:14.42 | starseeker | don't remember how that works |
| 20:15.20 | starseeker | vasc: I think you're looking for this? http://infobot.rikers.org/%23brlcad/ |
| 20:15.25 | gcibot_ | [ apt/ibot/infobot/purl logs for 2017 ] |
| 20:15.30 | vasc | yes. that's it! thanks! |
| 20:18.10 | mdtwenty[m] | I tried to make it bounded first so it would be easier to compare the results with a new solution, but if we were to alloc the array with the total number of segments, how we could do that? Since we only know that number after the count_hits kernel is executed |
| 20:19.26 | vasc | yeah but why would you need to know the size before calling count_hits anyway? |
| 20:19.59 | mdtwenty[m] | and when i tried to alloc the memory for that array before creating the opencl bufer, it would take to much time to execute comparing with the previous solution |
| 20:20.23 | vasc | eh? |
| 20:21.05 | vasc | in theory you'll only need to allocate buffers in the graphics card memory. |
| 20:22.02 | vasc | opencl buffers. |
| 20:22.52 | vasc | i don't see how allocating a smaller buffer will be slower than allocating a larger buffer. which is what will happen if you have 100 segments per pixel. |
| 20:27.27 | vasc | you're talking about this? |
| 20:27.28 | vasc | <PROTECTED> |
| 20:27.28 | vasc | <PROTECTED> |
| 20:27.28 | vasc | <PROTECTED> |
| 20:27.28 | vasc | <PROTECTED> |
| 20:27.28 | vasc | <PROTECTED> |
| 20:27.30 | vasc | <PROTECTED> |
| 20:27.32 | vasc | <PROTECTED> |
| 20:27.34 | vasc | <PROTECTED> |
| 20:27.36 | vasc | BU_ASSERT((counts[i-1] % 2) == 0); |
| 20:27.38 | vasc | h[i] = h[i-1] + counts[i-1]/2;/* number of segs is half the number of hits */ |
| 20:27.40 | vasc | <PROTECTED> |
| 20:27.42 | vasc | <PROTECTED> |
| 20:27.45 | vasc | that code is only there because we don't have opencl prefix sums implemented |
| 20:27.51 | Stragus | When the buffer runs out, you can return failure, realloc, then just try again with a bigger buffer and/or fewer rays? |
| 20:27.53 | vasc | it should be done all in the opencl side eventually. |
| 20:28.04 | vasc | you won't need to realloc |
| 20:28.11 | vasc | man |
| 20:28.55 | vasc | IIRC the max amount of partitions is 2x the amount of segments right? |
| 20:29.07 | vasc | so you just allocate that as the maximum buffer size. |
| 20:29.36 | vasc | and then you dynamically grow the virtual buffer, sure, but it will never go past the maximum buffer size. |
| 20:31.06 | Stragus | I seriously lack context here, but the maximum buffer size for buffering all hits through a complex scene can be astronomical. It's very practical to "return failure and try again", it almost never happens in practice |
| 20:31.21 | vasc | no it's not. |
| 20:32.00 | Stragus | Counting hits first also isn't relible since optimization of different kernels will produce slightly different results... besides the whole problem of tracing rays twice |
| 20:32.24 | vasc | allocating memory is much slower than counting hits. |
| 20:32.40 | Stragus | You allocate once and reuse the same buffer over and over |
| 20:32.46 | vasc | hm |
| 20:32.57 | vasc | sure that would work. |
| 20:33.04 | vasc | but why bother. |
| 20:33.12 | Stragus | It's the most efficient solution? |
| 20:33.22 | Stragus | has done exactly that in another ray tracer... |
| 20:33.24 | vasc | i would be happy with something that actually works first. |
| 20:33.41 | Stragus | Counting hits isn't reliable |
| 20:33.49 | vasc | why isn't it reliable? |
| 20:34.25 | Stragus | Because the kernel to count hits and the kernel to record hits are different. They use the same function, but they will all be inlined by the compiler and optimized in different rays |
| 20:34.29 | Stragus | Err, different ways* |
| 20:35.02 | vasc | so you're saying the opencl device won't produce the same results if you run the same code twice? that it isn't deterministic? |
| 20:35.21 | Stragus | It's not the same code, it's two different kernels: counting hints and recording hits |
| 20:35.33 | Stragus | Unless you actually have one kernel that does both with a branch. Less efficient though |
| 20:35.47 | vasc | it's the exact same code. except one stores the results and the other one doesn't. |
| 20:36.27 | Stragus | You do realize that everything OpenCL/CUDA is preferably inlined in the calling device function as one big fat function? |
| 20:36.41 | Stragus | And when you inline and optimize floating point math, results differ slightly |
| 20:36.50 | vasc | i don't see how that makes any difference in the code results. unless the compiler has a bug. |
| 20:36.56 | Stragus | (a+b)+c != a+(b+c) |
| 20:37.05 | vasc | especially because they both call the same exact functions. |
| 20:37.21 | vasc | man, i have it running and it works(tm) |
| 20:37.37 | vasc | i count the hits, alloc a buffer for the hits, and then store them |
| 20:37.40 | vasc | it's in SVN |
| 20:37.42 | Stragus | Okay, but it's not reliable if you enable optimization |
| 20:37.50 | vasc | why shouldn't it be? |
| 20:38.24 | Stragus | _If_ you use two separate kernels, it's all inlined and optimized separately, with slightly different results |
| 20:38.33 | Stragus | If you use a branch in the same kernel, it's fine, but slower |
| 20:38.37 | vasc | no man. because it's THE SAME KERNEL |
| 20:38.49 | vasc | they only difference is a branch which either stores the result or not. |
| 20:39.12 | vasc | :-) |
| 20:39.33 | Stragus | Okay, and you end up tracing rays twice |
| 20:40.10 | vasc | sure. |
| 20:40.17 | vasc | which still beats re-allocating memory. |
| 20:40.25 | Stragus | You don't reallocate! |
| 20:40.49 | vasc | sure. then you replace this simple to solve problem with a more complex problem. |
| 20:40.50 | Stragus | When I did something similar/identical, I had a batch of 32 buffers to store results (one buffer per thread/lane), the offsets were incremented by atomics, and there was a special flag to denote "I ran out of memory" |
| 20:41.02 | vasc | so which size of buffer will you allocate that can use all the gpu compute units? |
| 20:41.24 | vasc | my solution doesn't require atomics either. |
| 20:41.26 | Stragus | If that flag was ever set, you would reallocate _or_ trace less rays. And you did that maybe once, if the heuristics were off for the scene's complexity |
| 20:41.29 | vasc | its lockless. |
| 20:42.11 | Stragus | Wait actually, it wasn't one buffer per thread/lane, I was doing one atomic for the whole warp after counting how much memory all of it required |
| 20:42.21 | Stragus | The hits being buffered in on-chip shared memory |
| 20:42.55 | vasc | atomics don't work on shared memory. they work on global memory. |
| 20:43.00 | vasc | at least in opencl it's like that. |
| 20:43.34 | vasc | plus if you're doing inter-warp computation you don't need atomics. |
| 20:43.59 | Stragus | You have both in CUDA... but the atomics were for the global buffer, shared memory was only for accumulating many hits before flushing to global (with one atomic operation to allocate and flush the results of all threads of the warp) |
| 20:44.06 | vasc | ah ok. |
| 20:44.22 | vasc | you're still replacing a simple problem with a more complex problem. |
| 20:44.38 | Stragus | It's a little complex, but it's much faster than tracing twice |
| 20:45.08 | vasc | meh. there's way worse inneficiencies in the code right now. |
| 20:45.26 | Stragus | Okay then. :) Perhaps keep all this in mind for a future iteration |
| 20:45.37 | vasc | sure. |
| 20:47.39 | vasc | anyway mdtwenty[m], the problem with the change you made is that you can't assume that buffer will be large enough to hold the results. |
| 20:48.17 | mdtwenty[m] | yes i'm aware |
| 20:49.00 | mdtwenty[m] | and perharps i did something wrong when i tried to allocate the buffer for the array of segments in each partition |
| 20:49.25 | vasc | at one point we actually computed that prefix sum with opencl and did no memory transfers in that code, but the thing is i was using a prefix sum code with an Apache Public License code so it needed to be ripped out. |
| 20:49.54 | vasc | will need to either get an MIT licensed algorithm or reimplement it eventually. |
| 20:50.07 | vasc | but for now it doesn't matter. |
| 20:50.15 | vasc | well |
| 20:50.23 | vasc | i wouldn't be surprised if there was a bug there. |
| 20:50.53 | vasc | its okay to try things with a simpler piece of code for now, but eventually you need something that works properly. |
| 20:51.58 | mdtwenty[m] | yes the idea of implementing first this simpler code was to have a base to compare the results with future solutions |
| 20:52.44 | vasc | you could just make a mockup that returns white when there are intersections and black when there are none. |
| 20:52.52 | vasc | so it would make debugging your results easier. |
| 20:53.47 | vasc | i.e. a replacement for clt_shade_segs_kernel |
| 20:54.34 | mdtwenty[m] | yes thanks i will do that |
| 20:55.46 | vasc | eventually you'll need to get the material right as well. |
| 20:56.20 | vasc | where was that in the ANSI C code... |
| 21:03.42 | vasc | right |
| 21:03.58 | vasc | https://svn.code.sf.net/p/brlcad/code/brlcad/trunk/src/rt/view.c |
| 21:04.00 | vasc | colorview() |
| 21:05.32 | vasc | the opencl rt is basically a mix of ANSI C librt, liboptical and rt code... |
| 21:05.46 | vasc | with a lot of things deleted. |
| 21:06.11 | vasc | to make it something a human being can understand. |
| 21:06.45 | vasc | of course most of those features will probably need to be added back eventually. |
| 21:14.01 | mdtwenty[m] | sure :) |
| 21:14.55 | mdtwenty[m] | i will implement your suggestion of shading the intersections with a different color to see it there is still a problem with the weave_segs kernel |
| 21:15.37 | mdtwenty[m] | and will also work on replacing the bounded array |
| 21:19.09 | vasc | just make sure to keep backups |
| 21:19.43 | vasc | once you get a black/white shader working then message me. |
| 21:23.17 | vasc | i also started with before i got the shading working properly: |
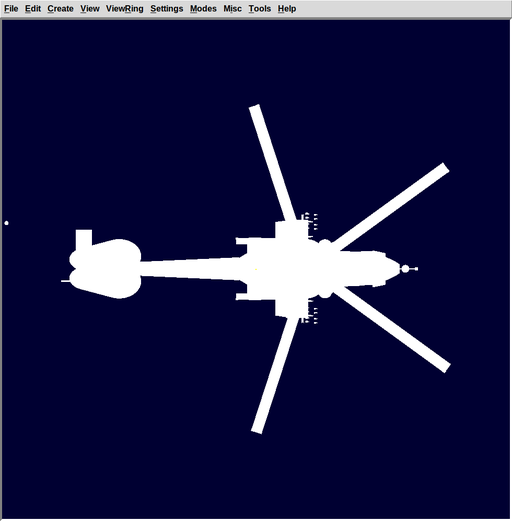
| 21:23.19 | vasc | https://brlcad.org/w/images/thumb/8/87/Cl_havoc.png/512px-Cl_havoc.png |
| 21:25.04 | vasc | s/started with/started with the black&white shader |
| 21:25.23 | mdtwenty[m] | yes it is definitely a good idea |
| 21:26.07 | mdtwenty[m] | i will implement that and will give you a heads up when its done :) |
| 21:38.02 | vasc | okay then |
| 21:38.32 | vasc | i notice you've been updating your blog, so keep at it |
| 21:43.38 | mdtwenty[m] | yes i will keep posting my daily progress on the blog! |
| 23:20.34 | *** join/#brlcad kintel (~kintel@unaffiliated/kintel) | |
| 23:40.31 | *** join/#brlcad teepee (~teepee@unaffiliated/teepee) | |
{kind=link}